Paper

Code
Abstract
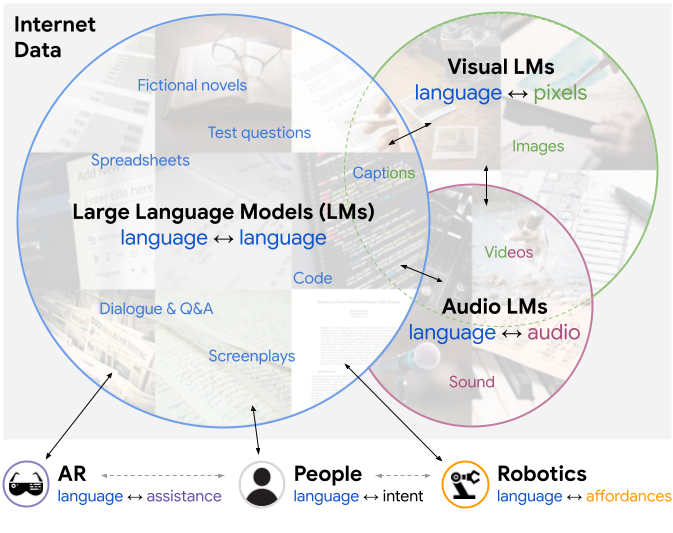
Large pretrained (e.g., “foundation”) models exhibit distinct capabilities depending on the domain of data they are trained on. While these domains are generic, they may only barely overlap. For example, visual-language models (VLMs) are trained on Internet-scale image captions, but large language models (LMs) are further trained on Internet-scale text with no images (e.g., spreadsheets, SAT questions, code). As a result, these models store different forms of commonsense knowledge across different domains. In this work, we show that this diversity is symbiotic, and can be leveraged through Socratic Models (SMs): a modular framework in which multiple pretrained models may be composed zero-shot i.e., via multimodal-informed prompting, to exchange information with each other and capture new multimodal capabilities, without requiring finetuning. With minimal engineering, SMs are not only competitive with state-of-the-art zero-shot image captioning and video-to-text retrieval, but also enable new applications such as (i) answering free-form questions about egocentric video, (ii) engaging in multimodal assistive dialogue with people (e.g., for cooking recipes) by interfacing with external APIs and databases (e.g., web search), and (iii) robot perception and planning.
Overview: Prompt Engineering Multimodal Applications
Socratic Models (SMs) is a framework in which multiple large pretrained models may be composed through language (via prompting) without requiring training, to perform new downstream multimodal tasks. This offers an alternative method for composing pretrained models that directly uses language as the intermediate representation by which the modules exchange information with each other. It is both distinct from, and may be complementary to, other multimodal approaches such as joint training a single model over all modalities. SMs are perhaps most intuitively understood through examples, which are provided throughout the paper.
Highlight: Zero-Shot Robot Perception and Planning
SMs can be used to enable robots to perform language-conditioned tasks. Our example system uses a VLM (open-vocabulary object detection with ViLD) to describe the objects in the scene, feeds that description as context to a LM as a multi-step planner (e.g., SayCan, Huang et al.), that then generates the individual steps to be passed to a pretrained language-conditioned robot policy (e.g., models similar to CLIPort for open vocabulary pick-and-place). Chaining this system together expands the set of language-specified tasks beyond the original set of primitives trained by the policy, and enables applications involving human dialogue with the robot.
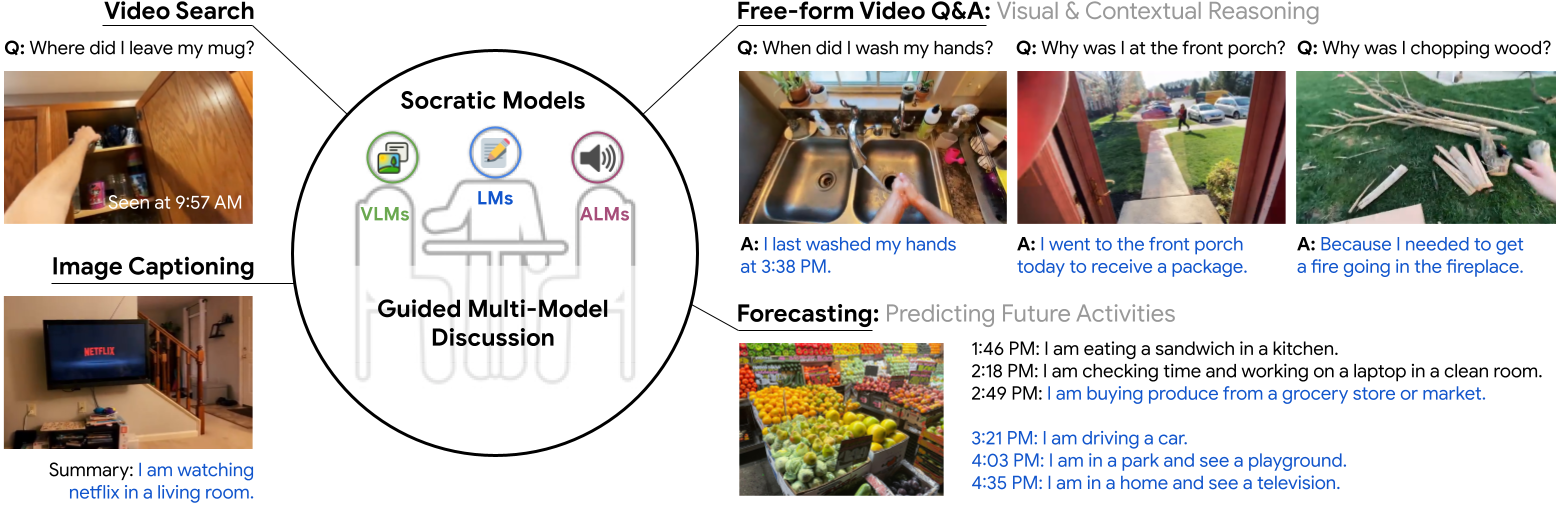
Highlight: Zero-shot Open-ended Reasoning (i.e., Q&A, Forecasting) on Egocentric Video
Our example Socratic-Model-based system for egocentric perception can respond to a variety of open-ended text prompts -- from generating free-form answers to contextual reasoning questions, to forecasting future activities:
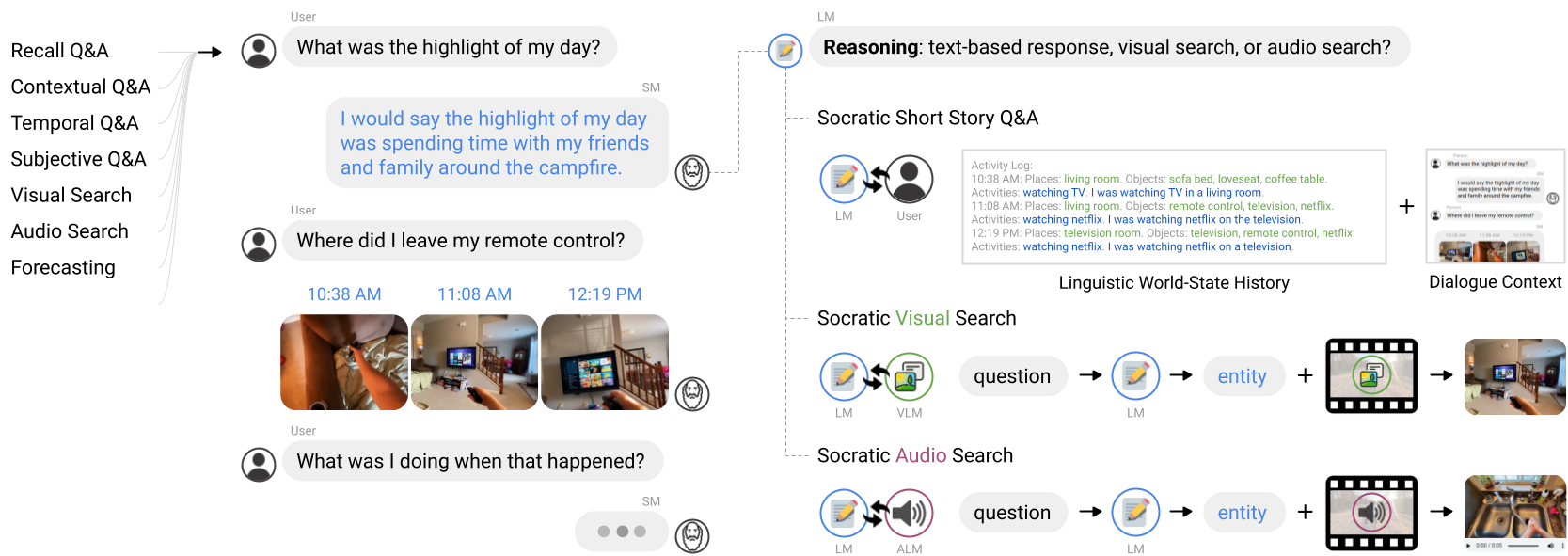
This works by formulating video understanding as reading comprehension, i.e., re-framing “video Q&A” as a “short story Q&A” problem, which differs from common paradigms for video understanding that may involve supervising video-text models on labeled datasets or adversarial training. To this end, we first extract a set of “key moments” throughout the video (e.g., via importance sampling, or video/audio search based on the input query, discussed in Appendix). We then caption the key frames indexed by these moments, and recursively summarize them into a language-based record of events, which we term a language-based world-state history. This is then passed as context to an LM to perform various reasoning tasks via text completion such as Q&A, for which LMs have demonstrated strong zero-shot performance. Drawing analogies to 3D vision and robotics, the world-state history can be thought of as building an on-the-fly reconstruction of events in the observable world with language, rather than other representations, such as dynamically-updated 3D meshes or neural fields.
Cody Wanner was very nice to let us use his video content in our example demonstration for our research. The examples above are all generated by using this video vlog as input:
Highlight: Multimodal Assistive Dialogue
SMs can be adapted to engage in multimodal dialogue to assist people in every day tasks, such as cooking. Our example application helps the user search for a recipe, then guides them through it step by step. The system allows the user to navigate recipe steps with dialogue, provides ingredient replacements or advice (using LM priors), and searches for visual references (images/videos) on user request. This is a case study in (i) prompting a dialogue LM to produce key phrase tokens that elicit specific Socratic interactions (e.g., video search via a VLM to output visual data), and (ii) using a web crawler as an additional module (in the form of external API) engaged in Socratic discussion with other models to retrieve information online. Here is a live demo (with narration):
Highlight: Zero-Shot Image Captioning
We can also compose foundation models to caption images zero-shot, through closed-loop Socratic dialogue:
Example captions below:

People gather under a blossoming cherry tree, enjoying the beauty of nature together.

At the outdoor market, you can find everything from plantains to Japanese bananas.

This image shows an inviting dining space with plenty of natural light.

A family celebrates a special occasion with ice cream and cake.

A wooden spoon and other kitchen utensils sit on a table in a restaurant kitchen.

A motorcycle lies abandoned in a sandy desert.

This photo captures a person enjoying a meal at a restaurant. The spinach and nasturtium garnish on the plate makes for a beautiful and healthy meal.

This cartoon shows one person enjoying a relaxing bath with their scrub bird.

This photo was taken at a restaurant or pier. You can see the person enjoying their meal with a beautiful view of the water.

The three people in this photo appear to be enjoying a close encounter with an elephant. This majestic creature looks like a gentle giant, and the handlers seem to have a great rapport with her. What a fun and unique experience for these tourists!
Highlight: Zero-Shot Video-to-Text Retrieval
We also can compose mutiple models to perform zero-shot video-to-text retrieval -- this achieves state-of-the-art for zero-shot methods, nearing the gap with finetuned-on-the-dataset methods:
Team













Robotics and Augmented Reality at Google
Method
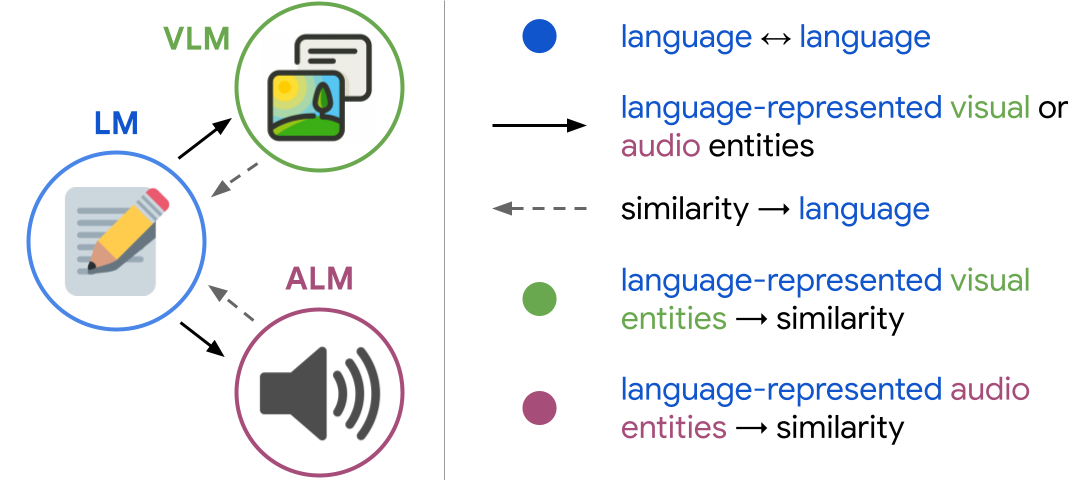
In this work we propose Socratic Models (SMs), a framework that uses structured dialogue between pre-existing foundation models, each of which can exhibit unique (but complementary) capabilities depending on the distributions of data on which they are trained. On various perceptual tasks, this work presents a case study of SMs with visual language models (VLMs, e.g., CLIP), large language models (LMs, e.g., GPT-3, RoBERTa), and audio language models (ALMs, e.g., Wav2CLIP, Speech2Text). From video search, to image captioning; from generating free-form answers to contextual reasoning questions, to forecasting future activities – SMs can provide meaningful results for complex tasks across classically challenging computer vision domains, without any model finetuning.
Examples of guided multi-model exchanges (Socratic Models) for an egocentric perception system: (i, left) parsing a natural language question into search entities (with LM) to be used to find the most relevant key moments in the video (with VLM); (ii, middle) describing each key frame by detecting places and objects (VLM), suggesting commonsense activities (LM), pruning the most likely activity (VLM), then generating a natural language summary (LM) of the SM interaction; (iii, right) concatenating key frame summaries into a language-based world-state history that an LM can use as context to answer the original question:
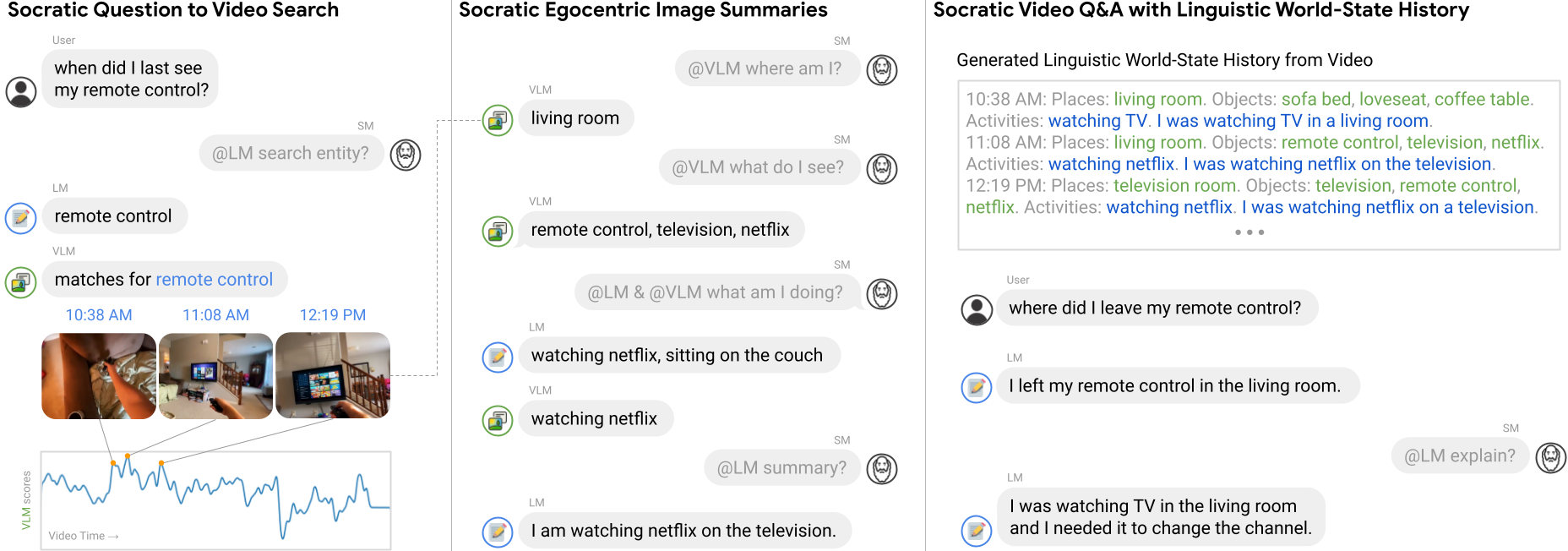
SMs can interface with the user through dialogue and perform a variety of tasks (formulated as Q&A) with egocentric video: sorting reasoning questions by their output modalities e.g., text-base responses, images from visual search, video snippets from audio search. Depending on the modality, each question can pass through a different sequence of Socratic interactions between the LM, VLM, and ALM:
Code
We plan to release prototypes in the form of self-contained colabs. They will be added to this repository and linked here:
• Image Captioning - Open in Colab
• Video Understanding (MSR-VTT) - Open in Colab
• Egocentric Video Q&A - Coming soon
• Robot Perception & Planning - Open in Colab
Citation
title={Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language},
author={Andy Zeng and Maria Attarian and Brian Ichter and Krzysztof Choromanski and Adrian Wong and Stefan Welker and Federico Tombari and Aveek Purohit and Michael Ryoo and Vikas Sindhwani and Johnny Lee and Vincent Vanhoucke and Pete Florence},
journal={arXiv},
year={2022}
}
Acknowledgements
We thank Debidatta Dwibedi, Matthew O’Kelly, and Kevin Zakka for excellent feedback on improving this manuscript, Anelia Angelova, Jean-Jacques Slotine, Jonathan Tompson, Shuran Song, for fruitful technical discussions, Kan Huang for applications support, Ahmed Omran, Aren Jensen, Malcolm Slaney, Karolis Misiunas for advice on audio models, and Cody Wanner for YouTube videos.